Instinctively, this should be downright simple. But I have been looking high and low for the last 3 days, and can't seem to find an example that shows the specification of a Unicode character numerically and have that assign the proper Unicode character to its position in an a sequential array, or print the proper glyph for that character.
Things seem to work OK for some characters, but others are not being assigned/displayed/printed correctly.
The test script I have is this:
#!/bin/sh
i=32
while [ $i -lt 255 ]
do
#echo '\u'$i
echo $i
i=$(expr ${i} + 1)
done |
LC_CTYPE=C awk 'BEGIN{
split( "", glyph ) ;
n=32 ;
}{
glyph[n] = sprintf("%c", $0 ) ;
n++ ;
}END{
for( n=32 ; n<256 ; n++ ){
printf("\t glyph[%d] = %c\n", n, glyph[n] ) ;
} ;
}'
Where things break down is captured in this snapshot:
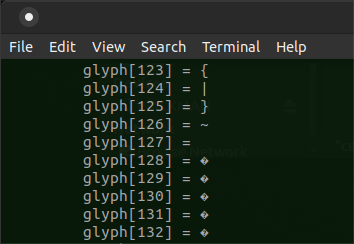
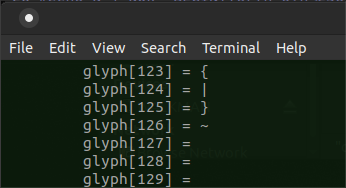
I tried using the following instead,
LC_CTYPE=en_US.UTF-8
but the results seem worse, rather than better:
Anyone know how to get the "value" or "glyph" assignment coded properly for proper display in MATE Terminal ?
I don't think it is relevant, but the Font used is "Liberation Sans".
Edit: I actually verified that the Fonts "C059" and "Deja Vu Sans Mono" both actually have glyphs defined for the character range 32-255, changed my MATE terminal profile, re-ran the script, and still have the same issue of either the character not being assigned correctly, or the glyph not being displayed correctly. Don't understand why !!! Real head-scratcher!
UM 22.04.5 LTS
Kernel 6.8.0-45-generic
MATE 1.26.0
Also, in that context, how to "properly" handle the single quote as one of the glyphs referenced numerically upon assignment, but subsequently referenced as character value of array position.
